It allows to keep PV going, with more focus towards AI, but keeping be one of the few truly independent places.
-
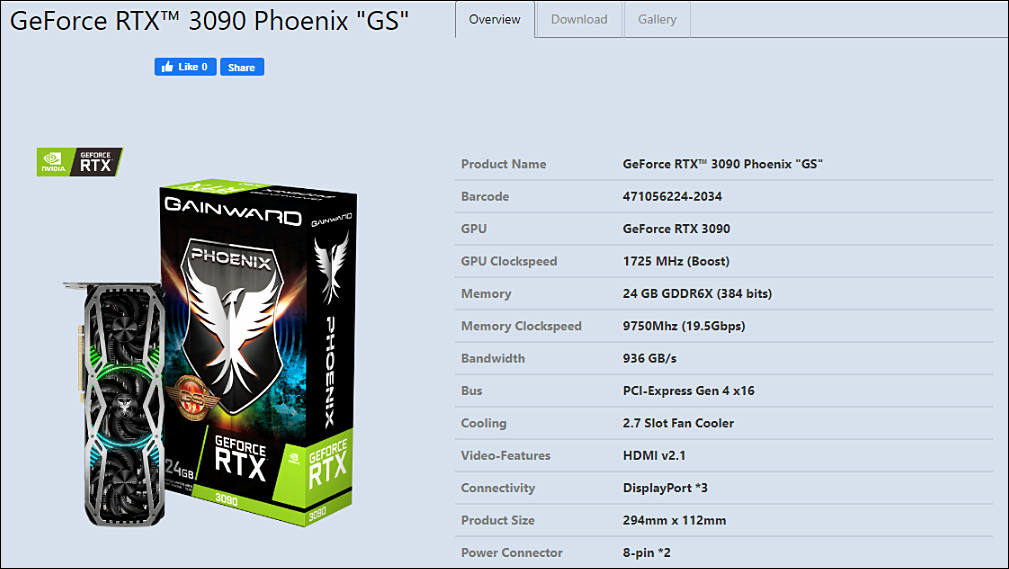
 sa14291.jpg1009 x 569 - 81K
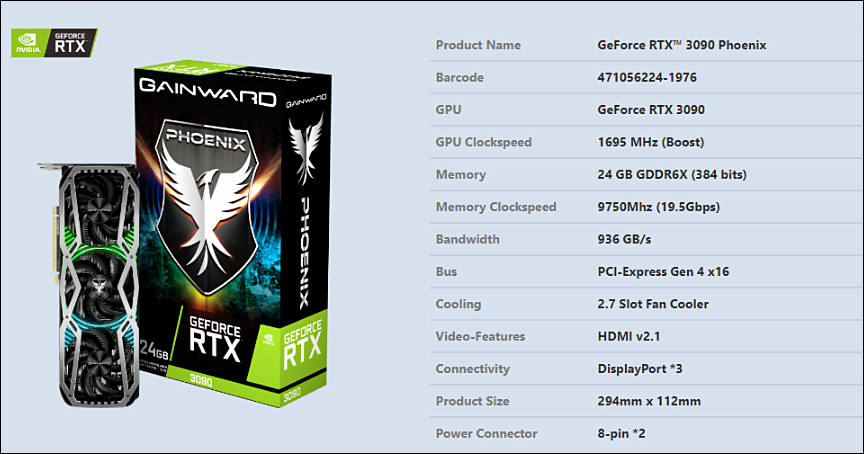
sa14291.jpg1009 x 569 - 81K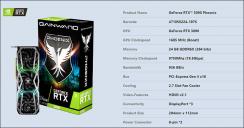 sa14292.jpg864 x 454 - 68K
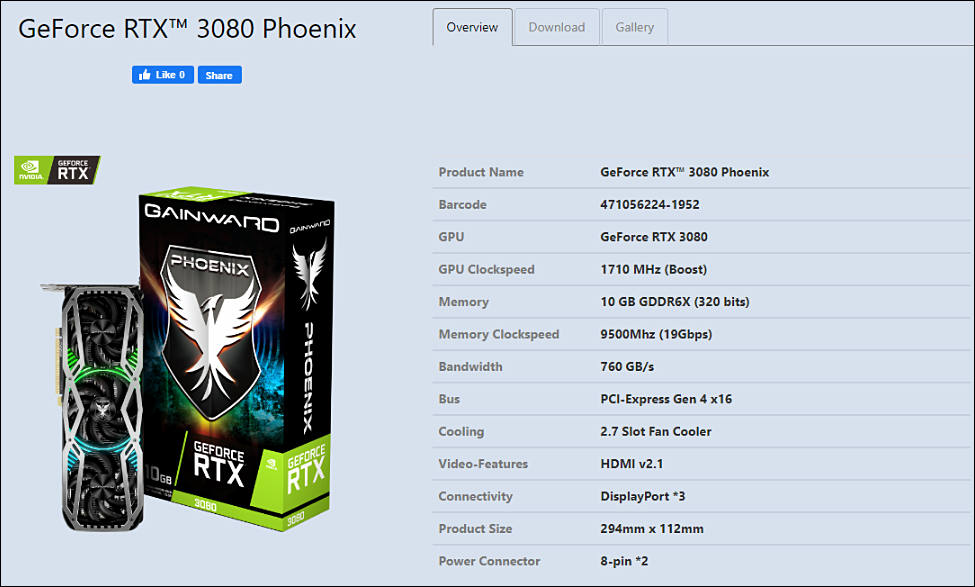
sa14292.jpg864 x 454 - 68K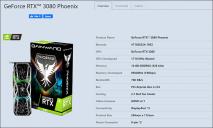 sa14293.jpg975 x 587 - 81K
sa14293.jpg975 x 587 - 81K -
So, do I get this right: 2080 ti (possibly in SLI) will stay the best affordable NVIDIA card for quite a while?
-
Can be even for 4-5 years. Note that RAM is important, as it makes sense to orient on GPU that will work with 8K properly.
And if you want cheap two used 1080 TI's are usually better 9and cheaper) in Resolve as I remember.
-
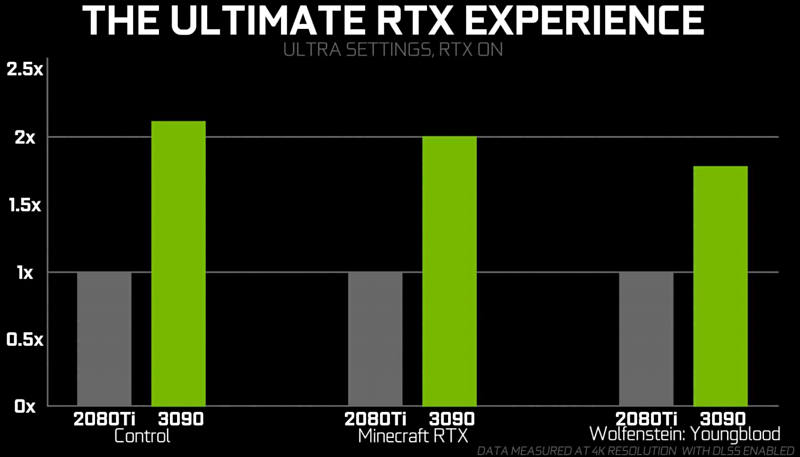
Some little fake charts, note that it is in DLSS mode and also using RTX and all on ultra settings.
Rumors are that as you drop settings and use native resolutions difference drops to 15-20%
 sa14301.jpg800 x 457 - 38K
sa14301.jpg800 x 457 - 38K -
RTX 3090 PCB


 sa14303.jpg800 x 517 - 98K
sa14303.jpg800 x 517 - 98K sa14304.jpg800 x 551 - 104K
sa14304.jpg800 x 551 - 104K -
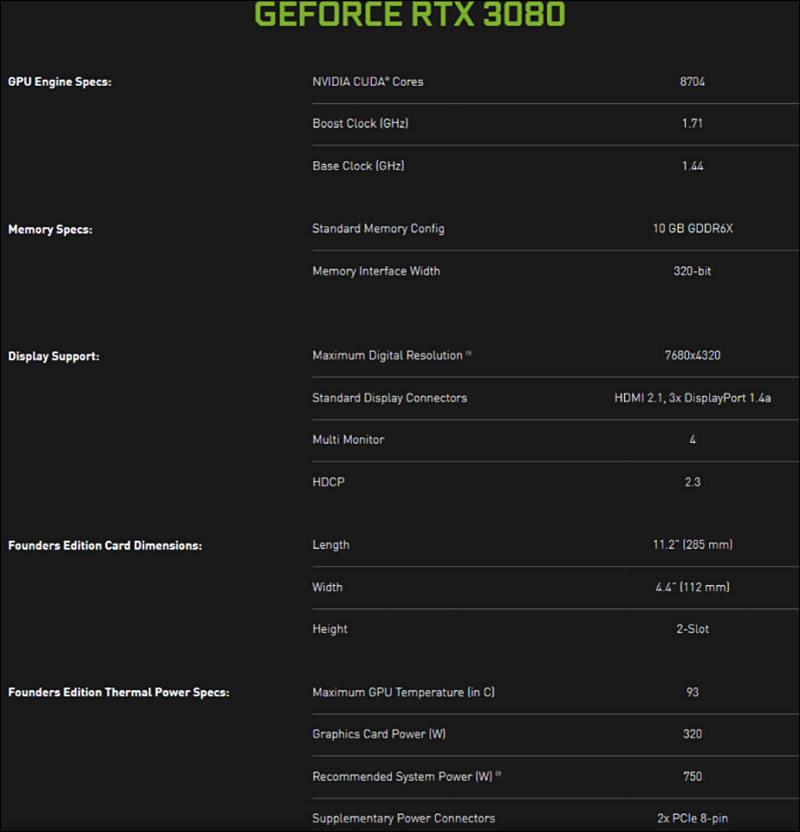
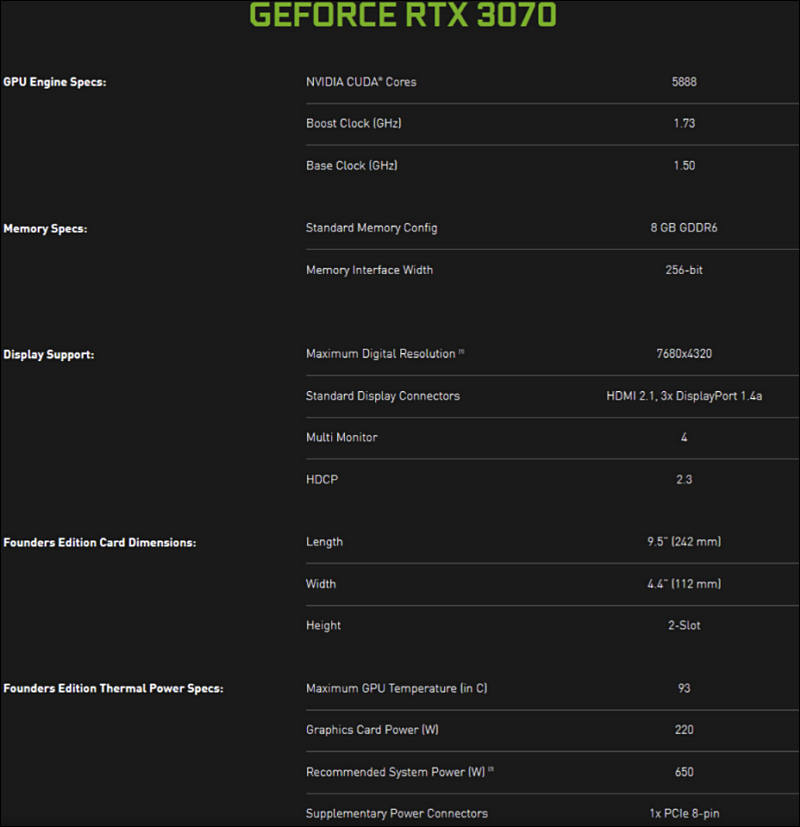
RTX 3080 GPU will sell for $699, the same as the current 2080, while the mid-range RTX 2070 will go for $499. NVIDIA says the RTX 3080 is twice as fast as the 2080, while the 3070 is even faster than the RTX 2080 Ti.
Nvidia specially lowered prices and moved RTX 3090 out of this event focus to avoid negative backslash.
The RTX 3080 willl feature 39 shader teraflops instead of just 11, and 58 RT TFLOPs, compared to 34. But Ampere's biggest leap is in its AI Tensor Cores, which clock in 238 tensor TFLOPs instead of just 89.
Nice marketing stunt to replace performance of FP32 into FP16, but this strange terms also need independent explanation.
Same strange
NVIDIA says the RTX 3090 can reach 36 shader teraflops, compared to the RTX 2080 Ti’s 13.4 TFLOPs.
-
Broadcast app that will be abandoned in 1-2 years completely




 sa14310.jpg800 x 434 - 49K
sa14310.jpg800 x 434 - 49K sa14311.jpg800 x 478 - 44K
sa14311.jpg800 x 478 - 44K sa14313.jpg800 x 465 - 41K
sa14313.jpg800 x 465 - 41K sa14312.jpg800 x 492 - 66K
sa14312.jpg800 x 492 - 66K sa14316.jpg800 x 448 - 36K
sa14316.jpg800 x 448 - 36K -
ASUS totally fucked the Nvidia idea with cooling improvement by mostly blocking third fan




 sa14319.jpg800 x 434 - 51K
sa14319.jpg800 x 434 - 51K sa14320.jpg800 x 529 - 54K
sa14320.jpg800 x 529 - 54K sa14317.jpg800 x 703 - 75K
sa14317.jpg800 x 703 - 75K sa14318.jpg800 x 535 - 59K
sa14318.jpg800 x 535 - 59K -
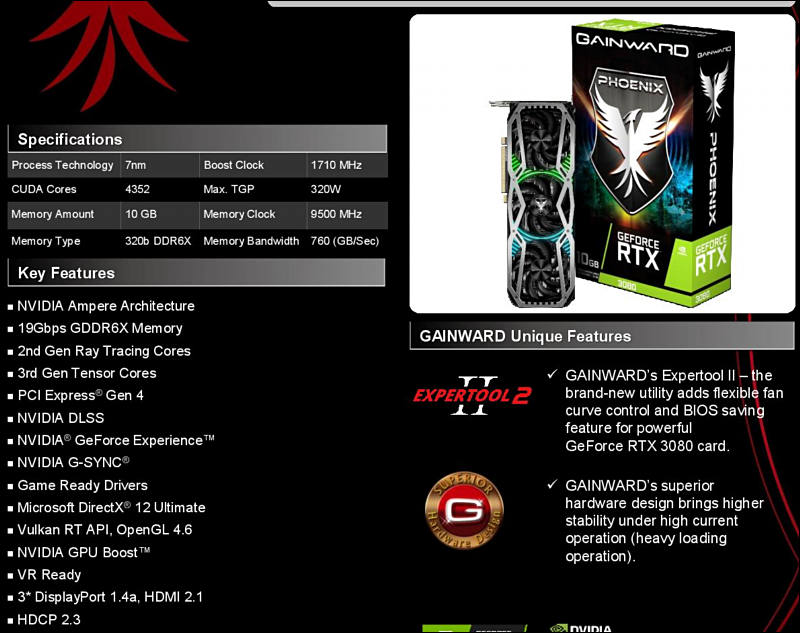
Specs
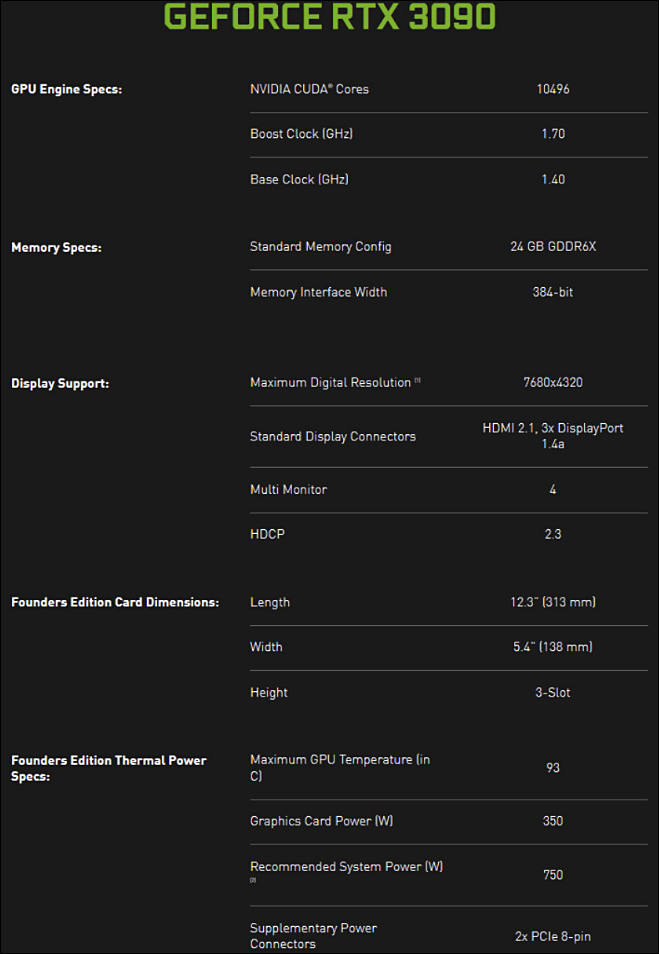
 sa14321.jpg659 x 954 - 59K
sa14321.jpg659 x 954 - 59K sa14322.jpg800 x 832 - 51K
sa14322.jpg800 x 832 - 51K sa14323.jpg800 x 827 - 52K
sa14323.jpg800 x 827 - 52K -
We have some real mess with CUDA cores counting, as in official ASUS PR it is 1/2 of Nvidia marketing number

And here is the explanation (yes it is Nvidia PR stunt!)
I have seen some people confused by Ampere’s CUDA core count. Seemingly out of nowhere, NVIDIA has doubled the core count per SM. Naturally, this raises the question of whether shenanigans are afoot. To understand exactly what NVIDIA means, we must take a look at Turing.
In Turing (and Volta), each SM subcore can execute 1 32-wide bundle of instructions per clock. However, it can only complete 16 FP32 operations per clock. One might wonder why NVIDIA would hobble their throughput like this. The answer is the ability to also execute 16 INT32 operations per clock, which was likely expected to prevent the rest of the SM (with 32-wide datapaths) from sitting idle. Evidently, this was not borne out.
Therefore, Ampere has moved back to executing 32 FP32 operations per SM subcore per clock. What NVIDIA has done is more accurately described as “undoing the 1/2 FP32 rate”.
As for performance, each Ampere “CUDA core” will be substantially less performant than in Turing because the other structures in the SM have not been doubled.
On pascal each SM contained 64 cuda cores, and each cuda core was a FP32 core. On turing, each SM contained 64 cuda core, and each cuda core was considered 1FP32 core + 1INT32 core. Now they doubled the FP32 cores per cuda core, but didnt mention anything about INT32 cores, so we supose now that each cuda core is 2FP32 + 1INT32, or if they doubled INT32 as well then it would be 2FP32 + 2INT32. The Tflops calculation were always based on FP32 anyways, so using the doubled cores is correct for the Tflops measurement since rasterization was always done on fp32. They also didnt release any info about register sizes, cache, rops, etc, so i believe the only doubled thing is the FP32 and the rest a smaller upgrade, otherwise it would be basically 2x turing lol.
They probably only doubled the FP32 logic because its the most used on games
 sa14325.jpg633 x 638 - 99K
sa14325.jpg633 x 638 - 99K -
@Vitaliy_Kiselev That FP32 numbers are confusing... does it mean those cards will instantly double in performance when used for Davinci Resolve (+NeatVideo), which rely heavily on FP32 calculations?
-
No, they won't. They doubled some ALU parts, but not all, all the buses and everything else are same as well as may be some have parts of shader cores.
Rumor is that actual performance gain is from 10% up to 25% per CUDA core in real tasks.
If you check - it was last minute marketing decision as all marketing materials even last week referenced proper amount of CUDA cores.
-
Industry source told that post-launch there will be "no stock will be available till the end of the year". The first wave of cards is said to be small, very, very small -- possibly the smallest launch in many years.
Stock will be extremely low for the next couple of months. Why? Samsung 8nm yields are bad at this point, NVIDIA might not want to make too many before the yields improve.
-
Some UK prices


 sa14352.jpg649 x 417 - 59K
sa14352.jpg649 x 417 - 59K sa14353.jpg658 x 419 - 54K
sa14353.jpg658 x 419 - 54K -
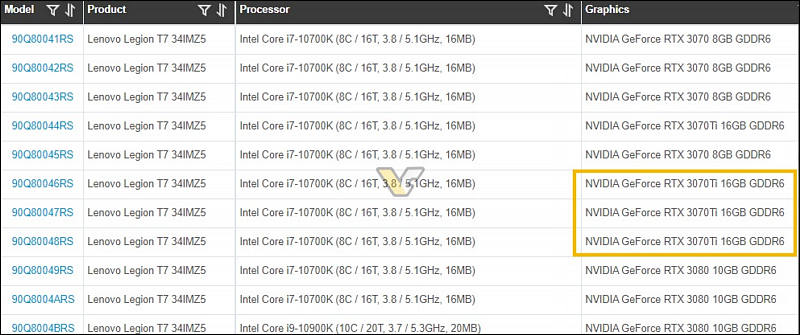
So upgrading form 1080ti to rtx3080 is going to make significant improvement for resolve studio?















Howdy, Stranger!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
- Topics List23,970
- Blog5,724
- General and News1,346
- Hacks and Patches1,153
- ↳ Top Settings33
- ↳ Beginners255
- ↳ Archives402
- ↳ Hacks News and Development56
- Cameras2,360
- ↳ Panasonic990
- ↳ Canon118
- ↳ Sony155
- ↳ Nikon96
- ↳ Pentax and Samsung70
- ↳ Olympus and Fujifilm100
- ↳ Compacts and Camcorders300
- ↳ Smartphones for video97
- ↳ Pro Video Cameras191
- ↳ BlackMagic and other raw cameras117
- Skill1,961
- ↳ Business and distribution66
- ↳ Preparation, scripts and legal38
- ↳ Art149
- ↳ Import, Convert, Exporting291
- ↳ Editors191
- ↳ Effects and stunts115
- ↳ Color grading197
- ↳ Sound and Music280
- ↳ Lighting96
- ↳ Software and storage tips267
- Gear5,414
- ↳ Filters, Adapters, Matte boxes344
- ↳ Lenses1,579
- ↳ Follow focus and gears93
- ↳ Sound498
- ↳ Lighting gear314
- ↳ Camera movement230
- ↳ Gimbals and copters302
- ↳ Rigs and related stuff272
- ↳ Power solutions83
- ↳ Monitors and viewfinders339
- ↳ Tripods and fluid heads139
- ↳ Storage286
- ↳ Computers and studio gear560
- ↳ VR and 3D248
- Showcase1,859
- Marketplace2,834
- Offtopic1,319


